· · Matthew Ford · 4 min read
Improving the Search Experience with OpenSearch (ElasticSearch)

In the modern world, where data is crucial for businesses and organisations, having efficient search and filtering capabilities is essential. Although traditional relational databases are effective in sorting through data, their limitations in handling large-scale search operations have led to the development of more specialised solutions like OpenSearch. OpenSearch is an open-source alternative to ElasticSearch, which is scalable, flexible, and extensible.
Based on our experience with our Ruby on Rails support client, the Trussell Trust, we will discuss the advantages and disadvantages of switching from MySQL to OpenSearch.
The Trussell Trust Data System is a web application created using Ruby on Rails. This system allows food banks nationwide to provide people in need with food and support. The application’s database contains a vouchers table with essential details such as the voucher’s status, client information, crisis causes, and the date and location of issuance and fulfilment.
In order for food banks to efficiently use vouchers, they need a search system to locate a voucher for a specific client quickly. Initially, we used MySQL queries with ActiveRecord, which worked well. However, as more vouchers were added to the system, search performance began to decline. Additionally, the system was constantly developing, resulting in new fields being added to the vouchers table, making compound MySQL indices more complex and indexing data taking longer. Eventually, the search reached a breaking point where MySQL query optimiser struggled to determine which index was required for a specific search, sometimes merging indices instead of using the desired one, resulting in poor performance. At worst, searches could take up to 30 seconds, with typical queries taking 1-5 seconds.
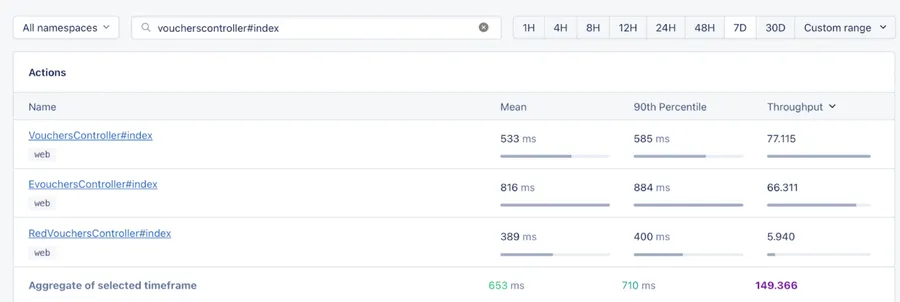
There was a problem that needed to be addressed. The application and database were overloaded with long requests, which was unnecessary. Additionally, maintaining complex indices became very challenging, as any adjustments to the search required significant development to ensure proper indexing.
That’s when we proposed the client switch to OpenSearch. And the switch itself was seamless. For integration with the Ruby on Rails application, we used searchkick with opensearch-ruby libraries. Searchkick provided developers with an easy-to-understand API to perform requests to the OpenSearch server. During development, we used the docker image provided and maintained by the OpenSearch team; while on production, we used Amazon’s OpenSearch Service to host our OpenSearch server. After the voucher record is saved, we update the index in the background with Sidekiq and Redis.
Since we needed to reindex millions of vouchers and wanted to avoid having significant downtime, we hid the new search form behind a feature flag. It provided us with multiple benefits: we could deploy the application at any point and de-risked the deployment as the users continued to use the old search. After the deployment, we could reindex the millions of records. Once the reindexing had finished, we could toggle the feature flag to enable OpenSearch without redeploying the application. And if there were any issues, we could quickly disable OpenSearch, bringing back the old search form and reducing any potential downtime to a minimum.
After the reindexing, we could finally see the benefits of the switch on production data. And we were satisfied. We saw a 5 to 10 times increase in performance. This immediately reduced the load to the application during peak times, reduced the load to MySQL database, making it more responsive with other queries and overall gave users a much more pleasant experience when they needed to use the search.
Besides the performance benefits, there are other advantages of using OpenSearch:
- OpenSearch is built with scalability in mind and can handle vast amounts of data and distribute the workload across multiple nodes.
- OpenSearch has excellent full-text search capabilities. Relational databases provide it to a degree, but they quickly fall short in more complex scenarios. OpenSearch offers advanced full-text search features such as stemming, tokenisation, phrase matching, fuzzy matching, and relevance ranking.
- OpenSearch offers various advanced search features: geospatial search, faceted search, query expansion, and result highlighting.
- OpenSearch is an open-source solution with an active community behind it. It encourages collaboration, innovation and continuous improvement. It also means that usually, integration of OpenSearch with any technology should be quick as there are open-source SDKs. And lastly, it also eliminates the need to pay for licensing fees you may encounter with proprietary search engines.
Should you start using OpenSearch right away? The answer is not straightforward. It depends on your specific use case. If you anticipate dealing with significant volumes of data, then OpenSearch might be a good fit for you. However, remember that there are a few potential drawbacks to consider if you don’t require extensive data-handling capabilities.
- Costs increase. Running a dedicated search engine on AWS costs money; if your application does not have a lot of data, then the price might outweigh the benefits you’ll get in the future.
- Increased complexity leads to more points of potential failure. Having everything stored in one place is significantly easier than ensuring the data is synced and available across multiple locations. If you use the database, you only have one point of failure – the database itself. On the other hand, with a dedicated OpenSearch server and indexing done in the background, we introduce two more links in the chain. If the Redis server goes down for whatever reason – records are no longer indexed, and data diverges. If the OpenSearch server is down – obviously, the search can no longer be performed as well.
- Any database migration or changes must be performed with indexing in mind. Migrating large volumes of data means that you need to reindex a lot of data at once, and it requires either time or costs associated with spinning up more servers for the workers that do the job.
Although relational databases may be efficient in the beginning, there comes a point where they can no longer perform searches efficiently. This is when the cumulative benefits of a dedicated search service outweigh any drawbacks.
Do you need help with your application?
At Bit Zesty, we specialise in building and maintaining bespoke software and integrating AI into existing applications.
Looking to build an application, but unsure of the price? Keen to discuss our experience, processes and availability?

